Forget LLM Brainrot: Introducing LoongRL
This new training method teaches AI to actually reason over massive documents, not just get confused. Here's how it works, in plain English.
Remember LLM Brainrot? The AI that forgets its own name, starts making things up, and generally acts like it needs a long, digital nap?
Related Reading: Does Your AI Have "Brainrot"? The Hilarious (and Terrifying) Truth About LLM Decay - From subtly silly responses to full-blown digital delirium, we explore why your favorite AI might be losing its mind…
You know that feeling when you ask your friend a deep, multi-part question, and by the time you're done, they've already pulled out their phone and just say, "Wait, what?"
That's basically every Large Language Model (LLM) right now.
Current AI models are great at short-term tasks. Ask them to solve a math problem or write a poem about a sad newt, and they're brilliant. But give them a 300-page PDF (a "long context") and ask them to find three scattered facts and tell you how they're related? Forget it. They'll get lost, bored, and probably just make something up. Their reasoning skills over long documents are, to put it kindly, terrible.
Well, Microsoft just dropped a new paper called LoongRL (which sounds like a How to Train Your Dragon character), and it's basically Ritalin for AI. It's a new way to teach models how to actually focus and reason over massive amounts of text.

How to Train Your (Loong) Dragon 🐉
Here's the genius part: LoongRL isn't a new model. It's a new training curriculum, and it's brilliantly diabolical.
The researchers at Microsoft are basically AI Dungeon Masters. Here's the scavenger hunt they built:
The Training Process
1. The Setup: They take a simple question, like, "What was the population of the city where the author of 'The Crimson River' was born?".
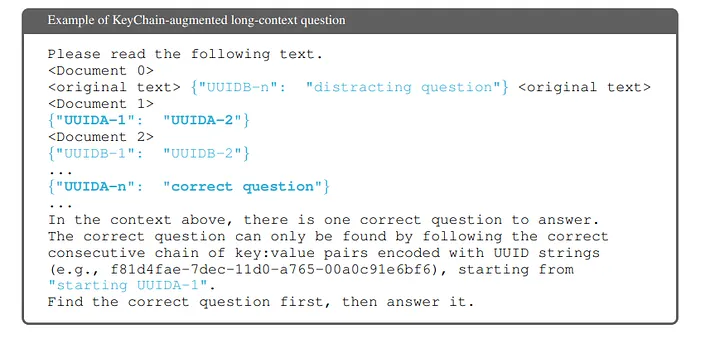
2. Hide the Question: They don't ask the AI this question. They hide the question itself inside a gigantic, noisy document (we're talking 128,000 tokens, which is like a whole novel).
3. The "KeyChain" Hunt: To find the question, the AI is given a starting "key" (e.g., UID-A). It has to scan the entire document to find UID-A. The "value" for that key is the next key, UID-B. Now it has to find UID-B, which points to UID-C, and so on, in a crazy chain across the whole text.
4. Add Distractors: To be extra mean (and smart), they throw in fake KeyChains that lead to dead ends and wrong questions. This teaches the AI to ignore junk.
5. Scatter the Answer: Once the AI finally finds the real question, the answer is also scattered. Document 1 might have the author's name, Document 4 might have their birthplace, and Document 7 might have that city's population data.
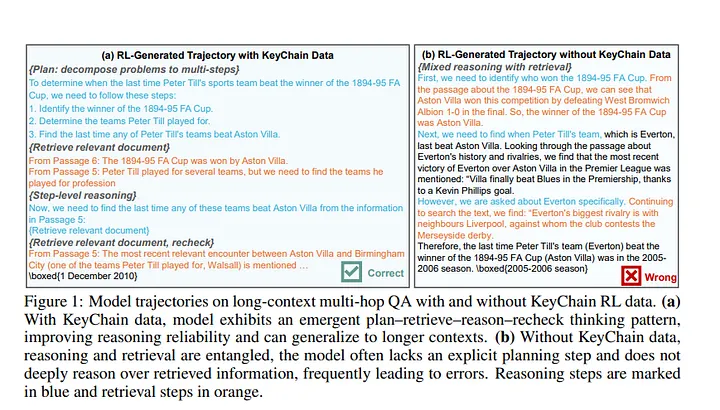
The Plan-Retrieve-Reason-Recheck Loop
This brutal training forces the AI to stop "speed reading" and actually develop an internal reasoning process. The paper calls this the Plan-Retrieve-Reason-Recheck loop. The AI learns to:
- Plan: "Okay, I need to find the author, then their city, then the population."
- Retrieve: "Found the author in Document 1!"
- Reason: "Okay, the author is Eleanor Vance. Now I need to find where she was born."
- Recheck: "Wait, this passage is ambiguous. Let me re-read that to be certain."
It's an AI that learns to think, plan, and even double-check its own work.
Future of AI & Use Cases (AKA: Why This Is a Big Deal)
An AI that can actually read and understand a 300-page report is a game-changer.
Medicine 👩⚕️
Forget an AI that just answers trivia. Imagine an AI that reads a patient's entire 20-year medical history, cross-references it with the 50 latest medical journals, traces the scattered symptoms, and suggests a diagnosis.
Law 🧑⚖️
Instead of 30 paralegals drowning in coffee, one AI could analyze 10,000 discovery documents, find the one contradictory email from 2019, trace the entire chain of evidence, and flag it.
Software Development 💻
An AI that can debug an entire codebase. Not just one function, but trace a user's bug report from the UI, through the API, down to the database, and back again.
Finance 💰
Auditing an entire company's financial records, not just a sample. Tracing every single transaction to find anomalies that are 10 steps removed from each other.
So… Is My GPT-4 a Potato Now? 🥔
Not quite. Think of it this way: current models (like GPT-4 or Claude 3) are General Practitioners. They're great at a lot of things.
Models trained with LoongRL are Specialists. They are the neurosurgeons of long-context reasoning.
This isn't a replacement; it's an evolution. The coolest part? A tiny 7-billion parameter model trained with LoongRL started outperforming models way bigger than it on these complex tasks. This means we're finally getting smarter, more efficient AI, not just bigger ones.
So, the next time you're drowning in a 100-reply email chain, just dream of the day a LoongRL-trained AI can read it for you, find the one sentence that matters, and tell you the potluck was moved to Friday.
What This Means for Cost Optimization
At Cost Katana, we're particularly excited about LoongRL because it represents a fundamental shift in AI efficiency:
- Smaller models, better results: This means lower API costs for the same or better performance
- Reduced token waste: Better reasoning means fewer retry attempts and hallucinations
- Smarter resource allocation: Use expensive models only when truly needed
- Real understanding, not guesswork: Fewer errors mean less manual intervention and lower operational costs
The future of AI isn't just about bigger models—it's about smarter, more efficient ones that can actually reason through complex problems without burning through your budget.
Paper Reference: LoongRL: Reinforcement Learning for Long-Context Reasoning
About the Author: Sourav Biswas is the Chief Product Officer at Cost Katana, where he leads the development of AI cost optimization solutions. He's also a tech entrepreneur, founder of Hypothesize, and passionate about building the future of human-AI interaction. Connect with Sourav on LinkedIn
Want to learn more about optimizing your AI costs while leveraging cutting-edge research like LoongRL? Get started with Cost Katana today.
Tags
Found this helpful? Share it!
Related Articles
Continue your learning journey with these related insights

Does Your AI Have "Brainrot"? The Hilarious (and Terrifying) Truth About LLM Decay
From subtly silly responses to full-blown digital delirium, we explore why your favorite AI might be losing its mind, and why startups are losing their shirts.

Sourav Biswas
October 22, 2024

How Much Does '1 AI' Cost? A (Hilariously) Simple Guide to AI Pricing
From your $20 ChatGPT subscription to the billion-dollar 'AI cost bubble' that's making startups cry. We break it all down.
Sourav Biswas
October 21, 2024

From AI Chaos to Cost Clarity: Why We Built CostKatana
A journey from AI cost blindness to complete visibility—and why every AI-powered business needs this intelligence.

Abdul Sagheer
January 18, 2026