
Company Story
From AI Chaos to Cost Clarity: Why We Built CostKatana
A journey from AI cost blindness to complete visibility—and why every AI-powered business needs this intelligence.

Abdul Sagheer
Co-Founder & CEO
January 18, 2026
8 min

Revolutionary Cortex Meta-Language and Provider-Independent Core transform AI processing. Generate complete answers across 400+ models without vendor lock-in.
Without an observability layer, LLM costs spiral out of control. Multiple providers, inefficient prompts, and redundant calls quickly bloat your bill.
CostKatana's Gateway intercepts requests and routes them to faster, cheaper alternatives that meet your quality requirements.
Duplicate requests are served directly from our semantic cache instead of hitting the provider again.
Malicious prompts are detected and blocked before reaching the LLM, preventing data exfiltration and costly API calls.
See everything in one place. Rich analytics help you understand AI spend, track performance, and find optimization opportunities.
The world's first AI meta-language that achieves 40-75% token reduction through revolutionary LISP-based answer generation.
$ npm install -g cost-katana-cli✓ Successfully installed cost-katana-cli@latest$ cost-katana optimize --cortex --input "Write a complete REST API"⚡ Cortex Meta-Language Processing...✓ Answer generated with 89% token reduction$ Cost savings: $0.45 per request→ Semantic integrity: 96%$ cost-katana --versioncost-katana-cli v2.1.0 | Cortex enabled ✓█
const response = await gateway.openai({
model: 'gpt-4o-mini',
messages: [{
role: 'user',
content: 'Write a REST API in Node.js'
}]
}, {
cortex: {
enabled: true,
mode: 'answer_generation',
dynamicInstructions: true
}
});
// 89% token reduction achieved!
console.log(response.metadata.cortex.tokenReduction);import cost_katana as ck
model = ck.GenerativeModel('claude-3-sonnet')
response = model.generate_content(
"Implement binary search algorithm",
cortex={
'enabled': True,
'mode': 'answer_generation',
'dynamic_instructions': True
}
)
# Massive savings with complete code generation
print(f"Savings: {response.cortex_metadata.cost_savings}")See the dramatic difference Cortex Meta-Language makes in your AI operations
Traditional AI Processing
Revolutionary Meta-Language
Monitor your AI costs in real-time, identify optimization opportunities, and watch your savings grow with our intelligent dashboard.
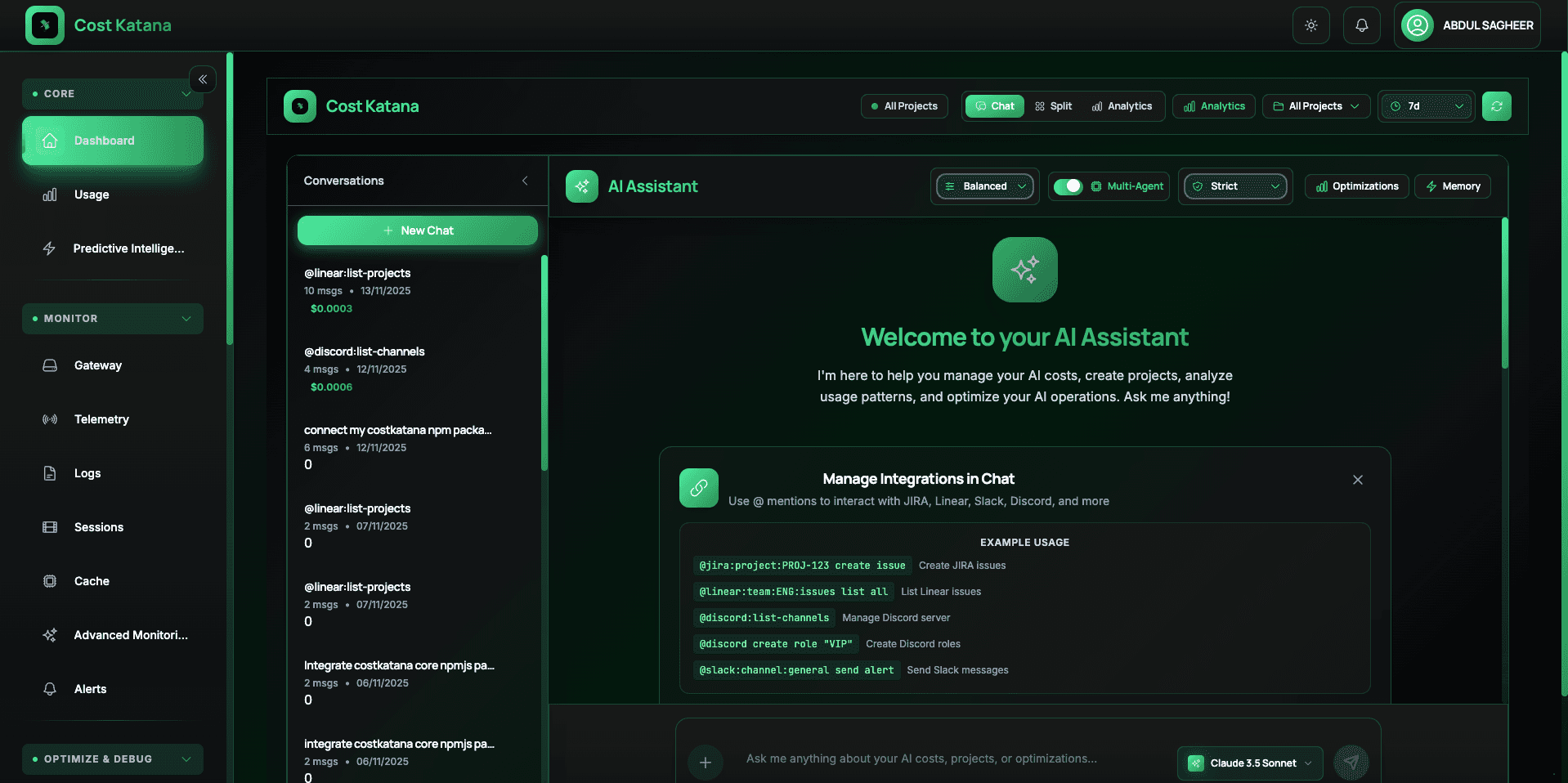
Track your AI spending patterns and discover automatic optimization opportunities that can slash your costs by up to 70% without sacrificing performance.
Get instant insights into your AI usage patterns, model performance, and cost breakdowns with beautiful, interactive charts and real-time updates.
Receive intelligent recommendations for model selection, prompt optimization, and resource allocation based on your specific usage patterns.
Integrate CostKatana into your stack with our comprehensive SDKs. Python, JavaScript, CLI tools - choose your preferred language and start optimizing AI costs. Choose your language and start optimizing.
Intelligent routing to cheaper models that meet quality requirements - instant cost savings
npm install cost-katananpm cost-katanaSemantic cache serves similar requests instantly - $0 cost, near-instant latency
npm install cost-katananpm cost-katanaEnterprise-grade tracing for all AI operations with hierarchical spans and cost attribution
npm install cost-katananpm cost-katanaTrack complete conversation flows with automatic cost attribution and session analytics
pip install cost-katanapip cost-katanaInteractive Python CLI for real-time AI cost optimization and analysis
pip install cost-katanapip cost-katanaNode.js command-line tools for prompt optimization, cost analysis, and agent trace management
npm install -g cost-katana-clinpm cost-katana-cli// Install: npm install cost-katana
import { createGatewayClient } from 'cost-katana';
// Create intelligent gateway with routing & caching
const gateway = createGatewayClient({
baseUrl: 'https://api.costkatana.com/api/gateway',
apiKey: process.env.COST_KATANA_API_KEY,
enableCache: true,
enableRetries: true,
intelligentRouting: true // Auto-route to cheaper models
});
// Gateway automatically routes to optimal model
const response = await gateway.openai({
model: 'gpt-4', // You request expensive model
messages: [{ role: 'user', content: 'Simple greeting' }],
qualityThreshold: 0.8
});
// Gateway routes to gpt-3.5-turbo instead - 90% cost savings!
console.log('Actual model used:', response.metadata.actualModel);
console.log('Cost saved:', response.metadata.costSaved);
console.log('Cache status:', response.metadata.cacheStatus);Leading organizations trust CostKatana to optimize their AI costs and improve performance
Connect with all major AI providers seamlessly. One platform, unlimited possibilities.
Get started with our comprehensive integration guide
View Integration GuideCommon AI cost challenges that keep developers and teams up at night
Unexpected bills from AI providers without visibility into what's driving the costs or which models are the culprits.
No clear breakdown of spending across different AI models and providers, making optimization impossible.
Difficulty measuring the business value and return on investment from AI implementations and spending.
Poor performance and latency issues without understanding which models or providers are causing bottlenecks.
Confusion about which AI model to use for specific tasks, balancing cost, quality, and performance.
Wasted spend on repeated or similar AI requests that could be cached or optimized for efficiency.
Security concerns and complexity of managing multiple API keys across different AI providers and environments.
Unpredictable monthly bills making it impossible to budget and plan for AI infrastructure costs.
Security vulnerabilities and malicious prompts that can lead to data breaches and unexpected costs.
Unexpected bills from AI providers without visibility into what's driving the costs or which models are the culprits.
No clear breakdown of spending across different AI models and providers, making optimization impossible.
Difficulty measuring the business value and return on investment from AI implementations and spending.
Poor performance and latency issues without understanding which models or providers are causing bottlenecks.
Confusion about which AI model to use for specific tasks, balancing cost, quality, and performance.
Wasted spend on repeated or similar AI requests that could be cached or optimized for efficiency.
Security concerns and complexity of managing multiple API keys across different AI providers and environments.
Unpredictable monthly bills making it impossible to budget and plan for AI infrastructure costs.
CostKatana solves all these problems with comprehensive AI cost optimization and monitoring
Get Started FreeComprehensive AI cost optimization tools designed to solve every problem and slash your expenses
Monitor AI usage, costs, and performance metrics in real-time with our comprehensive analytics dashboard.
Deep dive into spending patterns with detailed cost breakdowns and optimization recommendations.
Intelligent request routing and load balancing across multiple AI providers for optimal performance.
Complete tracing and monitoring with OpenTelemetry integration for enterprise-grade visibility.
Secure key management, prompt firewall protection, and agent trace orchestration.
Track AI costs from Zapier, Make, and n8n. Get complete visibility into every AI-powered step in your automation scenarios.
Start optimizing your AI costs today with our comprehensive platform
Start Free TrialExpert insights, research breakthroughs, and proven strategies for optimizing your AI infrastructure costs
A journey from AI cost blindness to complete visibility—and why every AI-powered business needs this intelligence.
Abdul Sagheer
Co-Founder & CEO
January 18, 2026
8 min

This new training method teaches AI to actually reason over massive documents, not just get confused. Here's how it works, in plain English.

Sourav Biswas
Chief Product Officer
October 25, 2024
4 min

From subtly silly responses to full-blown digital delirium, we explore why your favorite AI might be losing its mind, and why startups are losing their shirts.
Sourav Biswas
Chief Product Officer
October 22, 2024
6 min
Start for free, then pay for what you need. No hidden fees, no surprises.
For individuals and small projects.
For growing teams and startups.
For large-scale applications.
For enterprise-scale deployments.
See what's included in each plan
| Features | Free$0 | Plus$25/mo | Pro$499/mo | EnterpriseEnt.Custom |
|---|---|---|---|---|
User Restrictions | ||||
| Number of Seats | 1 | $25/month$25/mo | $499/month$499/mo | Custom |
| In App Token UsageToken Usage | 1M | 2M | 5M/month5M/mo | Unlimited |
| In App RequestsRequests | 5K | 10K | 50K | Unlimited |
| Number of Projects | 1 | 3 | 5 | Unlimited |
| Number of Agent Traces | 10 | 100 | 100/user | Unlimited |
| Number of Template Prompts | Unlimited | Unlimited | Unlimited | Unlimited |
| Number of Models | Cheaper models | All models | All models | All + Custom |
Analytics & Optimization | ||||
| Usage Tracking | ✓ | ✓ | ✓ | ✓ |
| Advanced Metrics | ✗ | ✓ | ✓ | ✓ |
| Predictive Analytics | ✗ | ✓ | ✓ | ✓ |
| Batch Processing | ✗ | ✓ | ✓ | ✓ |
Gateway & Security | ||||
| Unified Endpoint | ✓ | ✓ | ✓ | ✓ |
| Failover & Reliability | ✗ | ✓ | ✓ | ✓ |
| Security & Moderation | ✗ | ✓ | ✓ | ✓ |
Cortex Meta-Language (40-75% savings)REVOLUTIONARY | ✗ | ✗ | ✗ | ✓ Unlimited |
| Cross-Lingual Processing | ✗ | ✓ | ✓ | ✓ |
Support Channels | ||||
| Support Type | Community Forum | Community Forum | Community Forum | Discord & Slack |
Everything you need to know about Cost Katana and AI cost optimization
Cost Katana is an AI cost optimization platform that helps you reduce AI costs by up to 75% through intelligent features like Cortex optimization, semantic caching, model routing, and comprehensive monitoring. It provides real-time visibility into your AI spending across 300+ models from 12+ providers including OpenAI, Anthropic, Google, AWS Bedrock, and more.
Cost Katana typically delivers 40-75% cost savings through Cortex optimization and 70-80% additional savings through semantic caching. Our customers report average total savings of 60-85% on their AI infrastructure costs. The exact savings depend on your usage patterns, model selection, and optimization features enabled.
Getting started is simple: 1) Sign up for a free account at app.costkatana.com, 2) Install our SDK (npm install cost-katana), 3) Replace your existing AI provider calls with Cost Katana's unified API, 4) Configure your desired optimization settings. You can be up and running in under 10 minutes with immediate cost savings.
Cost Katana supports 300+ AI models across 12+ providers including OpenAI (GPT-4, GPT-3.5), Anthropic (Claude), Google (Gemini, PaLM), AWS Bedrock, xAI (Grok), DeepSeek, Mistral, Cohere, Meta (Llama), Azure OpenAI, HuggingFace, and Ollama. We continuously add new models and providers based on customer demand.
Cortex is our meta-language that converts natural language prompts into a more efficient, structured format. This reduces token usage by 40-75% while maintaining or improving output quality. Cortex uses semantic compression, redundancy elimination, and intelligent prompt engineering to minimize costs without sacrificing performance.
Semantic caching intelligently identifies similar requests and serves cached responses instead of making new API calls. Unlike traditional caching, it understands semantic similarity - so "summarize this document" and "create a summary of this text" would match. This can reduce costs by 70-80% for repeated or similar queries.
Yes, Cost Katana is built with enterprise-grade security. We offer Zero-Trust governance, multi-factor authentication (MFA), comprehensive audit logs, secure key vault management. Your data never leaves your control.
Cost Katana offers flexible pricing: Free tier with 10,000 requests/month, Startup plan at $49/month for growing teams, Pro plan at $199/month for scale, and Enterprise plans with custom pricing. All plans include core optimization features, with advanced features like custom models and dedicated support in higher tiers.
Integration typically takes 10-30 minutes for basic setup. Our SDK is designed as a drop-in replacement for existing AI provider SDKs. For complex enterprise deployments with custom requirements, implementation can take 1-3 days with our support team's assistance.
Cost Katana provides comprehensive monitoring including real-time cost tracking, performance metrics, model usage analytics, 65+ webhook events, OpenTelemetry observability, custom dashboards, alerts, and detailed reporting. You get full visibility into your AI infrastructure performance and costs.
Our intelligent routing automatically selects the most cost-effective model for each request based on complexity, required quality, latency requirements, and cost constraints. It can route simple queries to cheaper models while using premium models only when necessary, optimizing the cost-performance ratio.
Enterprise features include dedicated support, custom model fine-tuning, on-premises deployment, advanced governance controls, custom SLAs, priority feature requests, dedicated account management, and white-label options. Contact our enterprise team for a customized solution.
Our team is here to help you optimize your AI costs
Slash Your AI Costs. Today.
Built for AI-native teams and ambitious devs. Powered by Self-Improving AI with Data Network Effects and Zero-Trust Governance.